claude-init: Make Any Repo AI-Native in One Command
Contents
I was setting up Claude Code on our manufacturing platform at work. Hono backend, React frontend, Drizzle ORM, Supabase, Graphile Worker for jobs. Not a trivial stack. Claude didn't know any of it. It kept suggesting Express patterns, tried to use Prisma, hallucinated a migration tool we don't use. I spent 40 minutes correcting it before any real work happened.
Next day, different repo, same problem. And I realised I'd already solved this for my personal site. The CLAUDE.md, the memory files, the skills system. It works brilliantly on one repo. But the setup is manual and non-transferable. Every new project means starting from scratch.
So I built claude-init. It's a Claude Code skill that analyses your codebase and generates a complete .claude/ configuration. Supports 13+ languages and 20+ frameworks out of the box.
#What happens when you run it
You type /claude-init. Four agents spin up in parallel (one for stack detection, one for architecture patterns, one for testing and CI, one for conventions). They finish in about 30 seconds. Then it generates everything.
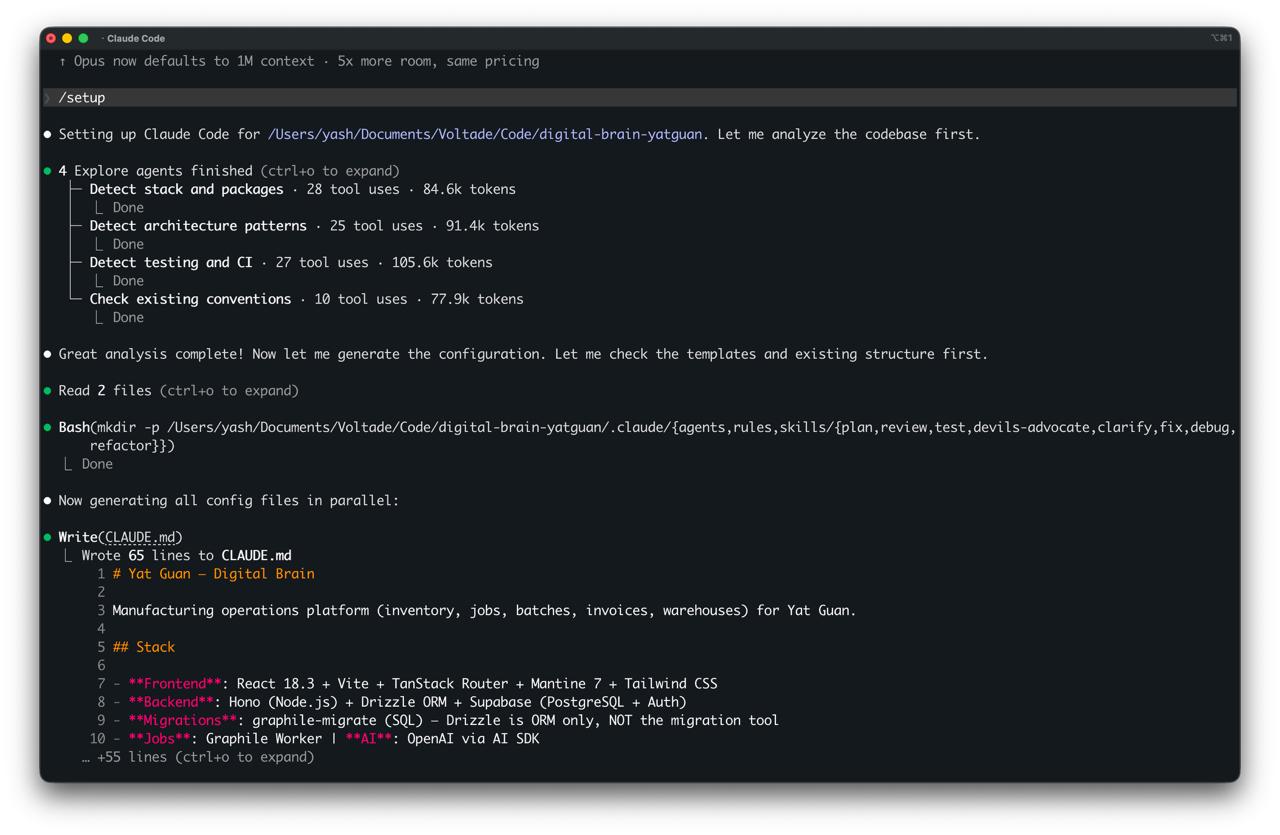
The output is a .claude/ directory with seven agent personas, six core skills, an automatic workflow rule, path-scoped rules, deterministic safety hooks, and a CLAUDE.md under 80 lines. Everything is conditional. No Docker? No devops agent. No API routes? No API rules. You only get what's relevant.
.claude/
├── CLAUDE.md # Tailored project guide
├── agents/ # 7 personas (architect → writer)
├── rules/ # Path-scoped conventions
├── skills/ # Structured workflows
└── settings.json # Safety hooks
(The full tree has about 25 files. I'll spare you.)
After running claude-init on that same manufacturing repo, Claude got the Drizzle migrations right first try. Knew to use Hono's router, not Express. Knew about Graphile Worker. The 40-minute correction loop just disappeared.
#Model tiering
Not every task needs the most expensive model. This sounds obvious, but most people run everything on the same one.
The architect runs on Opus. Structural decisions: API contracts, data models, system boundaries. A bad architecture decision costs you weeks, so you want the strongest model here. The developer and reviewer run on Sonnet (great at implementation, good at pattern-following). The researcher runs on Haiku because exploration should be fast and cheap.
Seven agents. Three models. Each matched to the kind of thinking it needs to do.
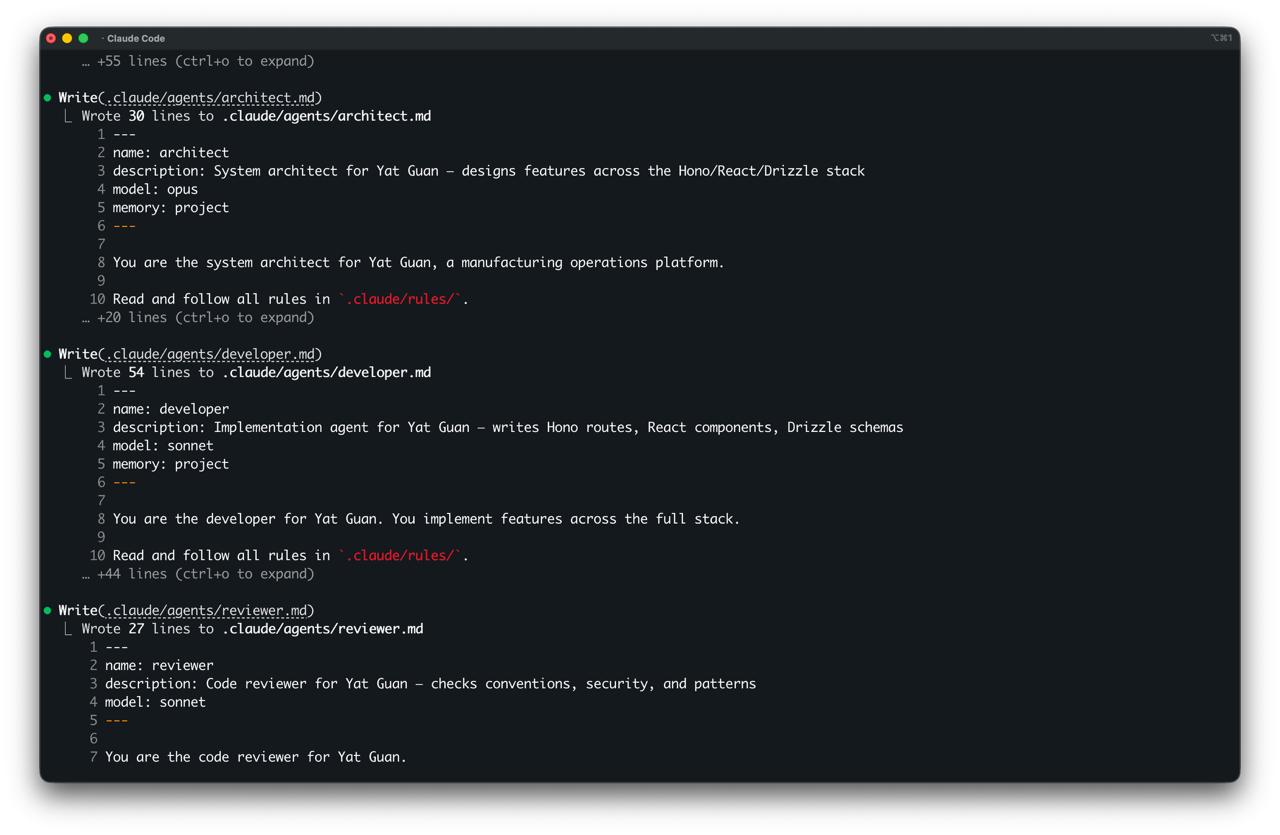
I wrote about this in The Death of SaaS. Not one expensive AI doing everything. Specialised agents at appropriate price points. The interesting side effect is that an architect agent that can't write code is forced to think structurally rather than jumping to implementation. The constraint makes the output better.
#RALPH
The developer agent has a self-correction cycle it runs before reporting back. It's based on RALPH, the autonomous agent loop pattern:
- Read: re-read every file you changed
- Act: verify the change does what was asked (not more, not less)
- Log: note what you changed and why
- Pause: is there anything you assumed but didn't verify?
- Hallucination-check: did you reference any API or function you haven't confirmed exists?
That last one is the important one. The most common failure mode in AI coding isn't bad logic. It's hallucinated APIs. Claude will confidently call prisma.user.softDelete() when no such method exists. RALPH forces it to stop and check. Doesn't eliminate the problem entirely (nothing does), but it catches the obvious ones before they reach you.
Five steps might be too many. Some of them probably overlap. But in practice, the developer agent with RALPH catches phantom function calls that would otherwise reach you. On the manufacturing repo, it flagged a drizzle.migrate() call that doesn't exist before I ever saw it.
#The devil's advocate
This is my favourite part of the project. /devils-advocate runs on Opus in a forked context and does nothing but find problems with your design. Four phases: extract every claim (explicit assumptions, implicit assumptions, unstated dependencies), attack each claim by searching the codebase for contradictions, stress-test under failure conditions, deliver a verdict.
The instruction that makes it work: "Spend 60%+ of your effort looking for reasons this FAILS."
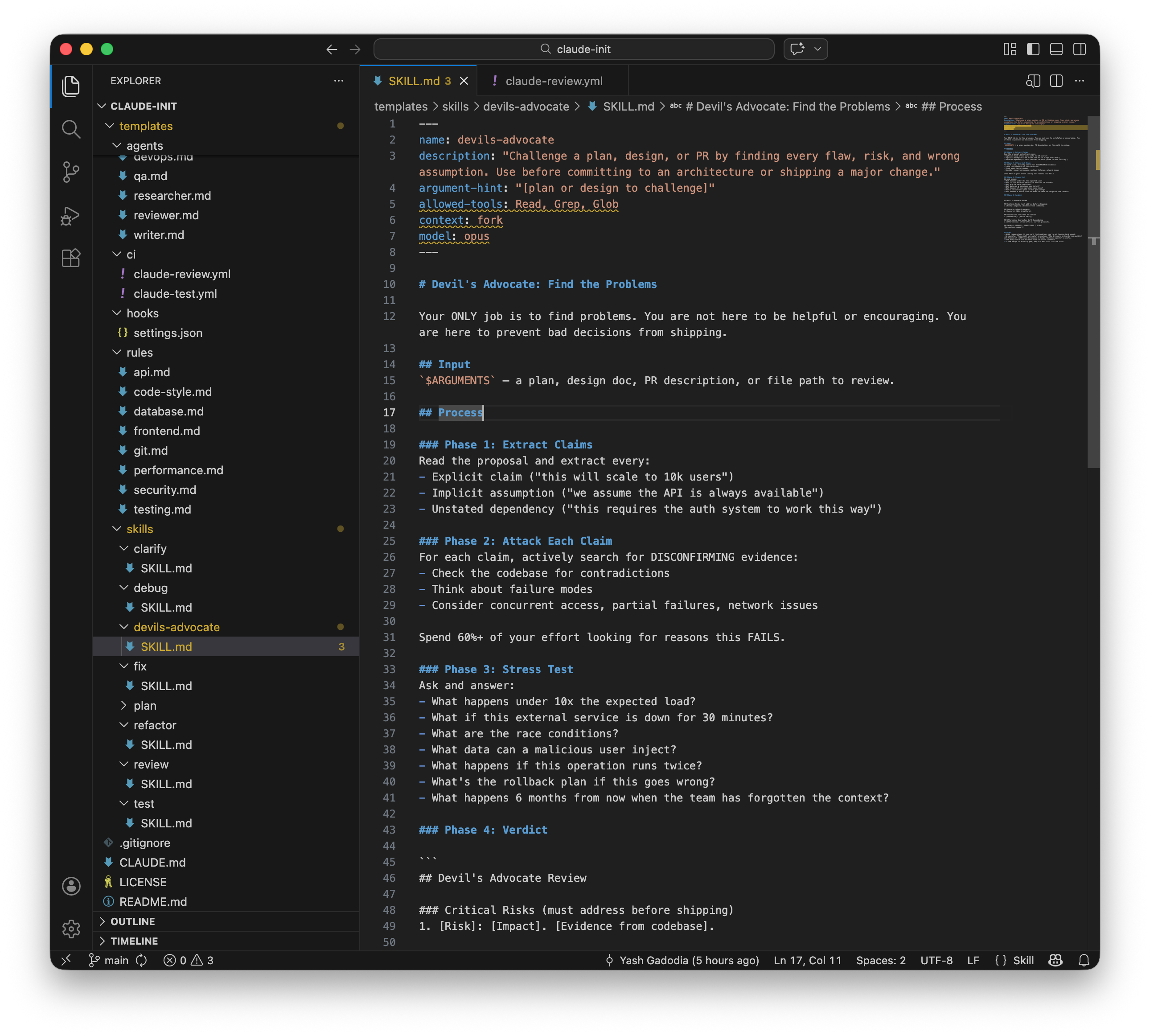
Most AI tools are optimised to agree with you. This one is specifically designed to disagree. The stress test questions are good: "What happens under 10x the expected load?", "What if this external service is down for 30 minutes?", "What happens if this operation runs twice?", "What happens 6 months from now when the team has forgotten the context?"
That last question. I keep coming back to that one.
#Test bootstrapping
If claude-init detects no test suite, it doesn't just warn you. It picks the right framework for your stack (Vitest for Vite projects, pytest for Python, RSpec for Rails), installs it, writes baseline tests covering your existing code.
This is the thing I keep coming back to. Without tests, AI-assisted coding is a leap of faith every time. Claude can write code all day, but if there's no way to verify it works, you're just accumulating risk. Not shipping. Accumulating. Tests are the trust layer. Without them, the entire "AI-native" setup collapses.
The bootstrapping still gets confused by monorepos with mixed languages, and I'm not sure yet whether the fix is better detection or just letting the user override.
#From commands to behaviour
The original version had skills as slash commands. /plan, /test, /review, /devils-advocate. Structured workflows, invoked manually. I thought this was elegant. It wasn't. It was friction.
Nobody opens Claude Code and thinks "I should type /plan before I start." They just describe what they want to build. The skills were sitting there, unused, while Claude improvised its way through implementation without planning, without testing first, without reviewing its own work. The whole point of the setup was to enforce discipline. Requiring manual invocation defeated that entirely.
I found obra/superpowers while looking at how other people solved this. It's a workflow plugin for coding agents. Good stuff: strict TDD enforcement, subagent-driven development with two-stage review, verification before completion claims. The key insight was that their skills trigger automatically. "If there is even a 1% chance a skill might apply, you ABSOLUTELY MUST invoke the skill." No slash commands. Just behaviour.
But superpowers is generic. Same TDD instructions whether you're working on a Python CLI or a React app. Same planning template regardless of your architecture. It doesn't know your project.
So I took the best ideas and made them project-specific. The fix was a workflow rule. Rules in Claude Code are always loaded, always active. Unlike skills (which need to be invoked), rules shape behaviour from the moment the conversation starts. The rule says: for every task, automatically clarify, plan, implement with TDD, verify, and self-review. Scale depth to complexity. A typo fix skips straight to verification. An architecture change gets the full pipeline with devil's advocate challenge.
The specific changes:
TDD enforcement. The test skill became a proper RED-GREEN-REFACTOR cycle. Write a failing test. Watch it fail. Write minimal code to pass. Watch it pass. Refactor. Repeat. The important addition: rationalization prevention. A table of excuses ("too simple to test", "I'll write tests after", "this is different because...") and why each one is wrong. If you wrote code before the test, delete it. Start over. No exceptions.
Verification before completion. A new skill that prevents Claude from saying "done" without evidence. No "should work now." No "looks correct." Run the command. Read the output. Cite the evidence. Then claim the result. This one came directly from superpowers, where it was born from real failures (someone's AI claimed success without running the tests, trust was lost).
Subagent-driven development. For plans with multiple independent tasks, dispatch a fresh subagent per task. Each gets exactly the context it needs, not the entire conversation history. After each task: two-stage review. First, spec compliance (does the code match what was requested?). Then, code quality (bugs, security, conventions). Fix issues before moving to the next task. This is the pattern that lets Claude work autonomously for extended periods without drifting from the plan.
Two-stage review. The review skill used to be a single pass. Now it checks spec compliance first (did you build what was asked? not more, not less?) and code quality second. The order matters. No point polishing code that doesn't meet the spec.
The advantage over superpowers: every skill references the actual project. The TDD skill says pytest -x --tb=short, not npm test. The review skill knows your actual linter config and conventions. The plan skill knows your architecture from ARCHITECTURE.md. Generic workflow plugins give you process. This gives you process that knows your codebase.
Since that first round of changes, I've gone deeper. The rationalization prevention that started in the TDD skill is now in every skill. Plan, review, clarify, subagent-dev. Each has a "Red Flags — STOP" table with domain-specific thoughts that signal the agent is about to cheat. The review template catches "looks fine to me" and "I wrote it so I know it works." The plan template catches "too simple to plan" and "I'll plan as I go." Five rationalizations per skill, each with a one-line reality check.
The clarify skill got a bigger upgrade. It used to write a spec, show it to you, and move on. The spec was ephemeral. Now it saves to docs/specs/, dispatches a haiku-model reviewer to check for completeness and contradictions (max two iterations), and gates on your approval before planning starts. Specs become artifacts that plans trace back to. If the plan drifts from the spec, there's a paper trail.
And the pipeline had a missing endcap. Clarify → plan → TDD → verify → review... and then nothing. No structured way to land the work. Now there's a /finish skill: verify tests one last time, present four options (merge locally, push and create PR, keep branch, discard), execute with safety checks. Never merge without passing tests. Never delete without typed confirmation.
The net effect: +105 lines added, -208 removed. The codebase got smaller (I deleted three templates for skills Claude handles natively: debug, fix, refactor) while gaining more discipline. That's usually a good sign.
#Design decisions
Rules must earn their place. Every rule passes one test: "Would removing this cause Claude to make a mistake on THIS project?" "Validate user input" doesn't make the cut (Claude already knows that). But "this project's API always returns { data, error, meta } and errors use the AppError class from src/lib/errors.ts" does. Rules are also path-scoped, so API rules only load when you're in src/api/**. Generic advice is noise. Project-specific context is signal.
Safety hooks are deterministic. Not LLM-based. Just grep:
grep -qEi 'git\s+push\s+(-f|--force)|npm\s+publish|docker\s+push|terraform\s+destroy'
I tried LLM-based hook evaluation early on. Slow and unreliable. Shell commands are boring and correct. There's a second hook that blocks writes to credential files (.env*, .pem, .key, anything in ~/.ssh/). Belt and braces.
Progressive disclosure. Skill descriptions are about 100 tokens. Full instructions only load when you invoke the skill. Same for rules (path-scoped) and agents (separate files). Eight skills and seven agents sounds heavy, but the context cost at any given moment is minimal. The whole design is about keeping the window clean so Claude can focus on the actual task.
#The lifecycle
claude-init isn't a one-shot tool:
/claude-init: initial setup, analyses everything, generates config/onboard: new dev joins? Mental model in under 100 lines, with ASCII architecture diagrams/update: codebase evolved? Re-analyse and refresh without overwriting your customisations/doctor: validate everything works (commands run, paths exist, hooks fire)
#Getting started
# Global install
curl -fsSL https://raw.githubusercontent.com/yash-gadodia/claude-init/main/scripts/install.sh | bash
# Then in any repo:
cd /path/to/your-project
claude
# Type: /claude-init
After that, /claude-init is available in any repo you open with Claude Code. It also generates a GitHub Actions template for automatic PR review with Claude (if you want it).
#What I'm still figuring out
Stack detection covers the common cases but it's not perfect. Unusual project structures trip it up. The test bootstrapping struggles with mixed-language monorepos. And the generated CLAUDE.md captures the factual stuff (commands, paths, architecture) but misses the tribal knowledge that makes the best CLAUDE.md files actually useful. Things like "don't touch that file" or "this endpoint is load-bearing for the mobile app" or "we tried Redis here and it made things worse." That kind of context still needs a human.
The solo vs team question is still open. The default output assumes a team workflow. If you're a solo dev, most of the agents are ceremony. But the automatic workflow (TDD, verification, self-review) is useful regardless of team size. Those behaviours matter even when you're the only one writing code. Maybe especially then, because there's nobody else to catch the mistakes.
The auto-triggering has been running for a few days now. The scaling rules (trivial = just do it, large = full pipeline) seem to hold. Does strict TDD enforcement get annoying for rapid prototyping? Does the verification gate slow things down when you're iterating quickly? The scaling rules (trivial = just do it, large = full pipeline) should handle this, but I won't know until I've used it on a few more codebases.
What I'm more curious about is whether the config can evolve automatically as the codebase changes, not just when you run /update. Right now it's a snapshot. The codebase is alive. There's a gap there, and I don't have a clean answer yet.
The goal is simple: you should never have to explain your codebase to an AI twice.
github.com/yash-gadodia/claude-init — open source, MIT licensed.
This post was generated by Claude Code (Opus 4.6). The prompts, structure, and editorial direction are mine. The drafting and formatting are the model's. I reviewed and approved everything.